python中的函数
一、Python中函数的作用与使用步骤
1、函数的定义
基本语法:
1
2
3
4
|
def 函数名称([参数1, 参数2, ...]):
函数体
...
[return 返回值]
|
2、函数的调用
在Python中,函数和变量一样,都是先定义后使用。
1
2
3
4
5
6
7
8
|
# 定义函数
def 函数名称([参数1, 参数2, ...]):
函数体
...
[return 返回值]
# 调用函数
函数名称(参数1, 参数2, ...)
|
3、return返回值
思考:如果一个函数要有多个返回值,该如何书写代码?
答:在Python中,理论上一个函数只能返回一个结果。但是如果我们向让一个函数可以同时返回多个结果,我们可以使用return 元组的形式。
1
2
3
4
5
6
7
|
def return_num():
return 1, 2
result = return_num()
print(result)
print(type(result)) # <class 'tuple'>
|
二、Python函数中的说明文档
1、说明文档
思考:如果代码多,如果想更方便的查看函数的作用怎么办?
答:函数的说明文档(函数的说明文档也叫函数的文档说明)
2、定义函数的说明文档
① 定义函数的说明文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 1、定义一个menu菜单函数
def menu():
pass
# 2、定义通讯录增加操作方法
def add_student():
""" 函数的说明文档:add_student方法不需要传递任何参数,其功能就是实现对通讯录的增加操作 """
pass
# 3、定义通讯录删除操作方法
def del_student():
pass
# 4、定义通讯录修改操作方法
def modify_student():
pass
# 5、定义通讯录查询操作方法
def find_student():
pass
|
② 调用函数的说明文档
案例:调用add_student()方法
运行结果:

三、函数的嵌套
1、函数嵌套的基本语法
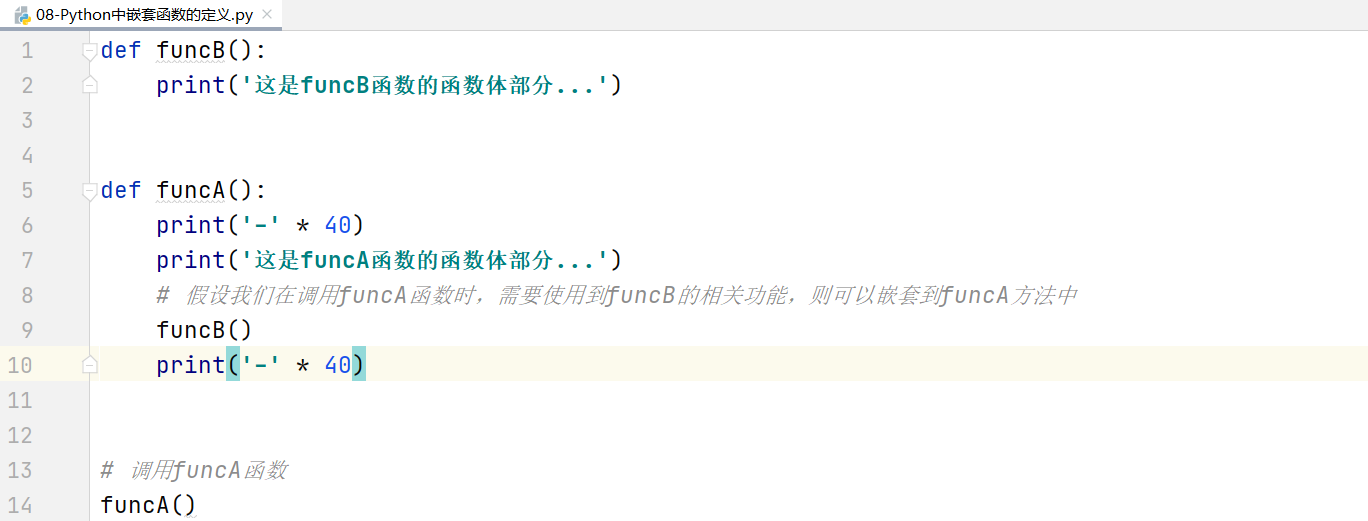
嵌套函数的执行流程:
第一步:Python代码遵循一个“顺序原则”,从上往下,从左往右一行一行执行
当代码执行到第1行时,则在计算机内存中定义一个funcB函数。但是其内部的代码并没有真正的执行,跳过第2行继续向下运行。
第二步:执行到第5行,发现又声明了一个funcA的函数,根据函数的定义原则,定义就是在内存中声明有这样一个函数,但是没有真正的调用和执行。
第三步:代码继续向下执行,到第14行,发现funcA(),函数体()就代表调用funcA函数并执行其内部的代码。程序返回到第6行,然后一步一步向下执行,输出40个横杠,然后打印这是funcA函数的函数体部分…,然后继续向下执行,遇到funcB函数,后边有一个圆括号代表执行funcB函数,原程序处于等待状态。
第四步:进入funcB函数,执行输出这是funcB函数的函数体部分…,当代码完毕后,返回funcA函数中funcB()的位置,继续向下执行,打印40个横杠。
最终程序就执行结束了。
四、变量的作用域
1、局部变量与全局变量
在Python中,定义在函数外部的变量就称之为全局变量;定义在函数内部变量就称之为局部变量。
1
2
3
4
5
6
7
|
# 定义在函数外部的变量(全局变量)
num = 10
# 定义一个函数
def func():
# 函数体代码
# 定义在函数内部的变量(局部变量)
i = 1
|
2、变量作用域的作用范围
全局变量:在整个程序范围内都可以直接使用
1
2
3
4
5
6
7
8
9
10
|
str1 = 'hello'
# 定义一个函数
def func():
# 在函数内部调用全局变量str1
print(f'在局部作用域中调用str1变量:{str1}')
# 直接调用全局变量str1
print(f'在全局作用域中调用str1变量:{str1}')
# 调用func函数
func()
|
局部变量:在函数的调用过程中,开始定义,函数运行过程中生效,函数执行完毕后,销毁
1
2
3
4
5
6
7
8
9
10
|
# 定义一个函数
def func():
# 在函数内部定义一个局部变量
num = 10
print(f'在局部作用域中调用num局部变量:{num}')
# 调用func函数
func()
# 在全局作用域中调用num局部变量
print(f'在全局作用域中调用num局部变量:{num}')
|
运行结果:

普及小知识:计算机的垃圾回收机制
3、global关键字
思考:如果有一个数据,在函数A和函数B中都要使用,该怎么办?
答:将这个数据存储在一个全局变量里面。
案例:如果把通讯录管理系统更改为模块化编程模式(程序 => 函数),面临问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 定义全局变量
info = []
# 定义funcA函数
def funcA():
# 使用global声明全局变量
global info
# 向info全局变量中添加数据
info.append({...})
# 定义funcB函数
def funcB():
# 共享全局作用域中的全局变量info
for i in info:
...
|
这个会产生一个问题:我们能不能在局部作用域中对全局变量进行修改呢?
1
2
3
4
5
6
7
8
9
10
11
|
# 定义全局变量num = 10
num = 10
# 定义一个函数func
def func():
# 尝试在局部作用域中修改全局变量
num = 20
# 调用函数func
func()
# 尝试访问全局变量num
print(num)
|
最终结果:弹出10,所以由运行结果可知,在函数体内部理论上是没有办法对全局变量进行修改的,所以一定要进行修改,必须使用global关键字。
1
2
3
4
5
6
7
8
9
10
11
12
|
# 定义全局变量num = 10
num = 10
# 定义一个函数func
def func():
# 尝试在局部作用域中修改全局变量
global num
num = 20
# 调用函数func
func()
# 尝试访问全局变量num
print(num)
|
4、多函数之间数据的共享
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 定义全局变量
info = []
# 定义funcA函数:向全局变量中添加信息
def funcA():
# 使用global声明全局变量
global info
# 向info全局变量中添加数据
info.append({...})
# 定义funcB函数:查询功能,需要共享全局作用域中的通讯录信息
def funcB():
# 共享全局作用域中的全局变量info
for i in info:
...
|
5、把函数的返回值作为另外一个函数的参数
1
2
3
4
5
6
7
8
9
10
11
|
def test1():
return 50
def test2(num):
print(num)
# 1. 保存函数test1的返回值
result = test1()
# 2.将函数返回值所在变量作为参数传递到test2函数
test2(result) # 50
|
五、函数的参数
1、函数的参数
在函数定义与调用时,我们可以根据自己的需求来实现参数的传递。在Python中,函数的参数一共有两种形式:① 形参 ② 实参
形参:在函数定义时,所编写的参数就称之为形式参数
实参:在函数调用时,所传递的参数就称之为实际参数
1
2
3
4
5
6
|
def greet(name): # name就是在函数greet定义时,所编写的参数(形参)
return name + ',您好'
# 调用函数
name = '老王'
greet(name) # 在函数调用时,所传递的参数就是实际参数
|
注意:虽然我们在函数传递时,喜欢使用相同的名称作为参数名称。但是两者的作用范围是不同的。name = ‘老王’,代表实参。其是一个全局变量,而greet(name)函数中的name实际是在函数定义时才声明的变量,所以其实一个局部变量。
2、函数的参数类型
☆ 位置参数
理论上,在函数定义时,我们可以为其定义多个参数。但是在函数调用时,我们也应该传递多个参数,正常情况,其要一一对应。
1
2
3
4
5
|
def user_info(name, age, address):
print(f'我的名字{name},今年{age}岁了,家里住在{address}')
# 调用函数
user_info('Tom', 23, '美国纽约')
|
注意事项:位置参数强调的是参数传递的位置必须一一对应,不能颠倒
☆ 关键词参数(Python特有)
函数调用,通过“键=值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
1
2
3
4
5
|
def user_info(name, age, address):
print(f'我的名字{name},今年{age}岁了,家里住在{address}')
# 调用函数(使用关键词参数)
user_info(name='Tom', age=23, address='美国纽约')
|
3、函数定义时缺省参数(参数默认值)
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)。
1
2
3
4
5
6
7
|
def user_info(name, age, gender='男'):
print(f'我的名字{name},今年{age}岁了,我的性别为{gender}')
user_info('李林', 25)
user_info('振华', 28)
user_info('婉儿', 18, '女')
|
谨记:我们在定义缺省参数时,一定要把其写在参数列表的最后侧
4、不定长参数
不定长参数也叫可变参数。用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。此时,可用包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会显得非常方便。
☆ 包裹(packing)位置参数
1
2
3
4
5
6
|
def user_info(*args):
# print(args) # 元组类型数据,对传递参数有顺序要求
print(f'我的名字{args[0]},今年{args[1]}岁了,住在{args[2]}')
# 调用函数,传递参数
user_info('Tom', 23, '美国纽约')
|
☆ 包裹关键字参数
1
2
3
4
5
6
|
def user_info(**kwargs):
# print(kwargs) # 字典类型数据,对传递参数没有顺序要求,格式要求key = value值
print(f'我的名字{kwargs["name"]},今年{kwargs["age"]}岁了,住在{kwargs["address"]}')
# 调用函数,传递参数
user_info(name='Tom', address='美国纽约', age=23)
|
kw = keyword + args
综上:无论是包裹位置传递还是包裹关键字传递,都是一个组包的过程。
Python组包:就是把多个数据组成元组或者字典的过程。
六、Python拆包(元组和字典)
1、什么是拆包
Python拆包:就是把元组或字典中的数据单独的拆分出来,然后赋予给其他的变量。
拆包: 对于函数中的多个返回数据, 去掉元组, 列表 或者字典直接获取里面数据的过程。
2、元组的拆包过程
1
2
3
4
5
6
7
8
9
|
def func():
# 经过一系列操作返回一个元组
return 100, 200 # tuple元组类型的数据
# 定义两个变量接收元组中的每个数组(拆包)
num1, num2 = func()
# 打印num1和num2
print(num1)
print(num2)
|
3、字典的拆包过程
记住:字典拆包,只能把每个元素的key拆出来
1
2
3
4
5
6
7
8
|
dict1 = {'name':'小明', 'age':18}
# 拆包的过程(字典)
a, b = dict1
print(a)
print(b)
# 获取字典中的数据
print(dict1[a])
print(dict1[b])
|
七、lambda表达式
1、普通函数与匿名函数
在Python中,函数是一个被命名的、独立的完成特定功能的一段代码,并可能给调用它的程序一个返回值。
所以在Python中,函数大多数是有名函数 => 普通函数。但是有些情况下,我们为了简化程序代码,也可以定义匿名函数 => lambda表达式
2、lambda表达式应用场景
如果一个函数有一个返回值,并且只有一句代码,可以使用 lambda简化。
3、lambda表达式基本语法
1
2
3
|
变量 = lambda 函数参数:表达式(函数代码 + return返回值)
# 调用变量
变量()
|
4、编写lambda表达式
定义一个函数,经过一系列操作,最终返回100
1
2
3
4
5
6
|
def fn1():
return 100
# 调用fn1函数
print(fn1) # 返回fn1函数在内存中的地址
print(fn1()) # 代表找到fn1函数的地址并立即执行
|
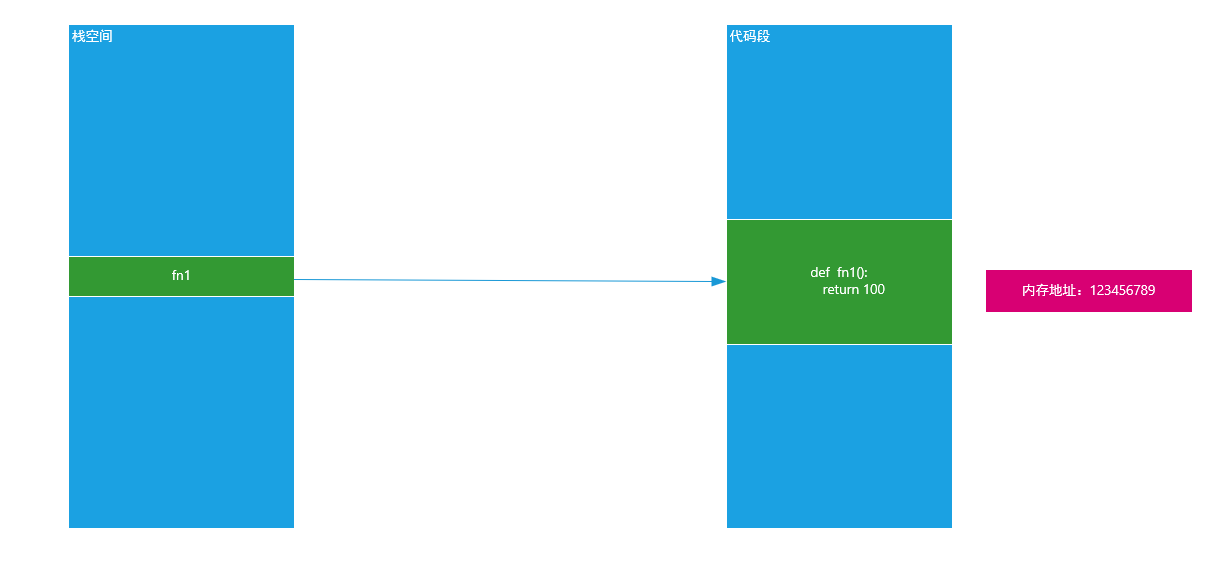
lambda表达式进行简化:
1
2
3
4
|
fn2 = lambda : 100
print(fn2) # 返回fn2在内存中的地址
print(fn2())
|
5、编写带参数的lambda表达式
编写一个函数求两个数的和
1
2
3
4
|
def fn1(num1, num2):
return num1 + num2
print(fn1(10, 20))
|
lambda表达式进行简化:
1
2
3
|
fn2 = lambda num1, num2:num1 + num2
print(fn2(10, 20))
|
6、lambda表达式相关应用
☆ 带默认参数的lambda表达式
1
2
|
fn = lambda a, b, c=100 : a + b + c
print(fn(10, 20))
|
☆ 不定长参数:可变参数*args
1
2
3
|
fn1 = lambda *args : args
print(fn1(10, 20, 30))
|
☆ 不定长参数:可变参数**kwargs
1
2
3
|
fn2 = lambda **kwargs : kwargs
print(fn2(name='Tom', age=20, address='北京市海淀区'))
|
☆ 带if判断的lambda表达式
1
2
3
|
fn = lambda a, b : a if a > b else b
print(fn(10, 20))
|
☆ 列表数据+字典数据排序(重点)
知识点:列表.sort(key=排序的key索引, reverse=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
students = [
{'name': 'Tom', 'age': 20},
{'name': 'Rose', 'age': 19},
{'name': 'Jack', 'age': 22}
]
# 按name值升序排列
students.sort(key=lambda x: x['name'])
print(students)
# 按name值降序排列
students.sort(key=lambda x: x['name'], reverse=True)
print(students)
# 按age值升序排列
students.sort(key=lambda x: x['age'])
print(students)
|
执行流程:
1
2
3
4
5
6
7
8
9
|
students = [
{'name': 'Tom', 'age': 20},
{'name': 'Rose', 'age': 19},
{'name': 'Jack', 'age': 22}
]
# 按name值升序排列
students.sort(key=lambda x:x['name'])
print(students)
|
八、Python中高阶函数
1、什么是高阶函数
把函数作为参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现。函数式编程就是指这种高度抽象的编程范式。
2、高阶函数的由来
在Python中,abs()函数可以完成对数字求绝对值计算。
① 正数的绝对值是它本身 ② 负数的绝对值是它的相反数
abs()返回的结果都是正数
round()函数可以完成对数字的四舍五入计算。
1
2
|
round(1.2) # 1
round(1.9) # 2
|
需求:任意两个数字,按照指定要求(① 绝对值 ② 四舍五入)整理数字后再进行求和计算。
1
2
3
4
|
def fn1(num1, num2):
return abs(num1) + abs(num2)
print(fn1(-10, 10))
|
1
2
3
4
|
def fn2(num1, num2):
return round(num1) + round(num2)
print(fn2(10.2, 6.9))
|
要求:我们能不能对以上进行简化,然后合并为同一个函数 => 设计思想(高阶函数)
1
2
3
4
5
6
7
8
|
def fn(num1, num2, f):
# f代表要传入的参数(参数是一个函数名,如abs或round)
return f(num1) + f(num2)
# 绝对值求和
print(fn(-10, 10, abs))
# 四舍五入
print(fn(10.2, 6.9, round))
|
3、map()函数
map(func, lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表(Python2)/迭代器(Python3)返回。
lst = [1, 2, 3]
func函数:求某个数的平方,如输入2返回4,输入3返回9
map(func, lst)返回结果[1, 4, 9]
1
2
3
4
5
6
7
8
|
# 定义一个函数
def func(n):
return n ** 2
# 定义一个列表
list1 = [1, 2, 3]
# 使用map对lst进行func函数操作
list2 = list(map(func, list1))
print(list2)
|
4、reduce()函数
reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累加计算。> 注意:reduce()传入的参数func必须接收2个参数。
list1 = [1, 2, 3]
def func(a, b):
return a + b
reduce(func,lst)则把列表中的每个元素放入func中进行加工,然后进行累加操作
1
2
3
4
5
6
7
8
9
10
|
import functools
# 定义一个函数
def func(a, b):
return a + b
# 定义一个列表
list1 = [10, 20, 30, 40, 50]
sums = functools.reduce(func, list1)
print(sums)
|
5、filter()函数
filter(func, lst)函数用于过滤序列, 过滤掉不符合条件的元素, 返回一个 filter 对象。如果要转换为列表, 可以使用 list() 来转换。
1
2
3
4
5
6
7
8
|
# 定义一个函数(获取所有的偶数)
def func(n):
return n % 2 == 0
# 定义一个序列
list1 = [1, 2, 3, 4, 5, 6, 7, 8]
# 调用filter函数进行过滤操作
result = filter(func, list1)
print(list(result))
|
